
Road to Malware Analyst Part 1 - Art of Disassembly

Hello all. Welcome to part 1 of my malware analysis Substack. This will go over the basics of assembly: the what, why, and how.
I will warn you now, you may be discouraged after reading. Don’t let it get to you! A guaranteed 6-figure salary isn’t supposed to be easy, anon.
Let’s begin.
How Executables Work
To be able to reverse engineer software, you need a solid understanding of how software programs execute. You are going back in time and interpreting modernly written code through a 1950s lens. You are going to the lowest possible level of executable code and discovering higher level behavior.
To have even a chance at comprehending reverse engineering, you need to understand the premise of computer memory. Knowing compiled, lower level languages like C/C++ will help you translate the necessary skills.
Everyone says “computers only read 1s and 0s”. That’s true, but there’s so much more to that statement. These 1s and 0s (bits) are transposed into bytes (8 bits). These bytes are representative of computer instructions aka opcodes. These instructions are, well, instructions. They tell the computer (CPU) what to do.
An instruction is the primitive computer behavior. Remember when I said we were going back to the 1950s? These instructions are akin to the punch-cards used during that time to program machines. They perform basic actions like moving data, pushing and popping data from the stack (memory), and calling functions.
Modern programmers don’t worry about such primitivism as compilers are capable of translating the code we write today into these instructions (called machine code). Interpreted languages like Python work slightly differently as they use a Virtual Machine (VM) to translate the produced bytecode to display an output.
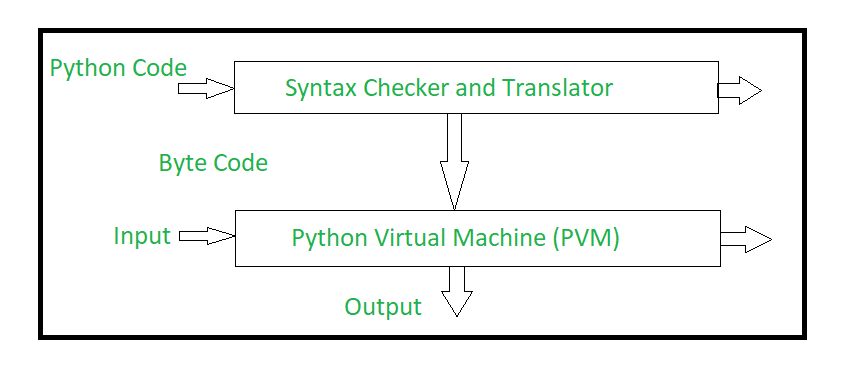
The Other Way Round
Reverse engineers take this produced machine code and go backwards. Machine language is translated into assembly language. The translation is not perfect, however. Various optimizations and name mangling/gouging make interpreting the assembly instructions harder than it already is. The process of going backwards from machine language to assembly is called disassembling. The practice of analyzing disassembled code is called static analysis. There’s also dynamic analysis, which is the runtime analyzation of a program. We will cover this in a future post.
It is possible to go back even higher from the assembly code, displaying it as a translated high-level language. This process is called decompiling and allows the reverse engineer better understand code flow when compared to assembly analysis.

Popular disassemblers:
IDA Pro ($$$)
Hands down the greatest disassembler and decompiler on the market. It is ungodly expensive (plus they just shifted to a subscription model). If you try hard enough, you might be able to “find” it for free.
They do provide a freeware program, but you are very limited in what you can do with it.
Ghidra (free)
The NSA’s open source disassembler. It is the second greatest gift the NSA has given us, just behind the EternalBlue exploit. It uses the Snowman decompiler for built-in decompilation.
Binary Ninja ($$)
Binja is a popular and quickly improving disassembler. It costs a fair amount of money for commercial use. There’s also a 75% student discount. The Binja team is very involved with the community and responds well to feedback. I’ve never used it, but a friend of mine says it’s worth the money.
Radare2 (free)
For you vim maxis out there. Radare is a terminal-based disassembler. It’s open source and extremely lightweight, but it has a large learning curve since it uses a bunch of keyboard shortcuts (just like vim).
Cutter (free)
Cutter is the GUI version of Radare2. It’s more sleek and nicer on the eyes than Ghidra IMHO.
Decompilers:
Snowman (free)
Open source and embedded into many different disassemblers. It usually provides decent output and is constantly improving.
JD-GUI (free)
Used for decompiling Java programs. Java programs are special as they use a virtual machine (JVM) to run, thus this decompiler is used for them.
Hex-Rays ($$$)
Decompiler included with IDA Pro. Provides incredibly accurate and optimized outputs, but it is extremely expensive.
Assembly Language
As mentioned before, disassembled code is turned into assembly language. Here’s another visual reference.

My examples will be done in x86 assembly. Yes, just about every machine is running x64 nowadays, but malware is still consistently written in x86 as x64 systems can still run them. There are a few minor changes between x86 and x64 assembly which will be discussed in a later post.
Let’s discuss the core concepts of assembly language:
Instructions
We’ve already discussed them earlier. These perform basic instructions for the CPU to execute. Think basic arithmetic, reading and writing data, and calling functions.
Registers
Think of registers like variables. Registers simply hold data (on x86, they hold 32 bits of data). At the core of all programming languages, all variables are stored either as digits or references to digits.
Register sizes can be reinterpreted depending on need.


Special Registers
ESP
Called the “stack pointer”. We will discuss stack shortly, but ESP is in charge of keeping track of the size of the stack during instruction calls. It always points to the top of the stack.
Called the “base pointer”. EBP is in charge of the stack frame. EBP is prepared as a function is called, setting up its “frame”. ESP shifts up and down as the stack changes size during a function’s instructions. EBP is a pointer to the top of the stack when a function is first called. This is used to manage function parameters and the function return address.
EIP
Called the “instruction pointer”. EIP points to the next instruction to be executed. With the use of jumps and calls, instruction execution does not always move linearly, thus EIP is used.
ESI/EDI
Called “source index” and “destination index”. Commonly used as source/destination pointers for instructions that copy memory.
Basic Instructions
I will use Intel syntax for assembly instruction examples. There is also AT&T syntax but I’ve never seen a disassembler use AT&T.
A basic example of an assembly instruction:
mov eax, 0x30
We are performing the mov instruction on register eax, moving 0x30 into its bit space.
Don’t let the presentation of the instructions scare you. This is literally the same as eax = 0x30.
Let’s look at more (; means comment):
mov eax, ebx ; Copy the value of ebx into eax
mov ecx, [0xBADDF00D] ; Copy the value at address 0xBADDF00D into ecx. Think of using brackets [] as dereferencing a pointer
mov ebx, [ecx] ; Copy the value at address ecx into ebx
mov edx, [ecx+4] ; Copy the value at address ecx + 4 into edx
Let’s convert the above into C pseudocode:
eax = ebx;
ecx = *0xBADDF00D;
ebx = *ecx;
edx = *(ecx+4);
Now let’s do some math:
mov eax, 0x1F
mov ebx, 0x20
add eax, ebx ; Adds eax and ebx and stores the value in eax
C:
eax = 0x1F;
ebx = 0x20;
eax = eax + ebx;
Easy enough, right?
Most arithmetic instructions store the resulting value in the first register. Think of them as +=, -=, *= operations. Division is an exception, see below:

What’s the difference between these 2 instructions?
mov eax, 0
xor eax, eax
“Nothing. They do the same thing”
Yes, they both set EAX to 0. But, the mov instruction is slower than the xor instruction. xor is smaller and faster than mov. This is a basic compiler optimization. If you see a register XORing itself, know that it is now 0.
What is happening here?
mov eax, [ebp+8]
lea ebx, [ebp+8]
We haven’t gone over lea yet. It stands for “Load Effective Address”. The difference between mov and lea is that mov loads the value, whereas lea loads the address.
Let’s interpret it as C pseudocode:
int eax = *(int *)(ebp+8);
int *ebx = (int *)ebp+8;
printf(“%d\n”, eax == *ebx);
Would output “1”.
The Stack
If you’ve taken any LeetCode courses, you know what a stack is. The stack is a data structure characterized by pushing and popping. Its behavior first-in, last-out (FILO/LIFO). Think of a stack like a stack of plates. You can only take the top plate off of the stack. I.E. if you want to take off the bottom plate, you need to take off all of the plates above it first.
Memory for functions, local variables, and flow control is stored in a stack. EBP points to the stop of the stack within a current function frame, and ESP always points to the top of the current stack.
Visual example of stack usage:


What gets stored in the stack?
Local variables, function parameters and return addresses, and occasions where registers need their values to be temporarily saved.
Let’s look at a basic C function (Compiled in Windows):
int Foo(int bar, int baz)
{
return bar + baz;
}
Disassembled:
int __cdecl Foo(int, int)
push ebp
mov ebp, esp
mov eax, [ebp+0x08]
add eax, [ebp+0x0C]
pop ebp
retn
A lot to unwind here, but let’s go through it piece by piece.
push ebp
The value at register EBP is pushed onto the stack. The stack increases in size by 4 bytes.
mov ebp, esp
Value at ESP is copied to EBP. This sets up EBP to be the start of the stack of the function frame.
mov eax, [ebp+0x08]
The value at address EBP + 0x08 is copied into EAX. This appears to be a random value, however this references one of the parameters in the function. 0x08 is the first parameter in the function (bar), and 0x0C (12) is the second parameter in the function. If you’re still confused, say it out loud, “the value at address EBP plus 8 is equal to the value of the first parameter in the function. The value at address EBP plus 12 is equal to the value of the second parameter in the function.”
Quick digression: the assembly stack grows “downwards”. ESP is the top of the stack, ESP + 4 is the second-highest value in the stack, ESP+8 is third, and so on. We are moving 4 bytes at a time because x86 has a 32-bit (4 byte) register size (x64 has 64-bit register size aka 8 bytes, so we would adjust if disassembling 64-bit programs).
add eax, [ebp+0x0C]
The value stored at address EBP + 0x0C is added to EAX with the sum stored in EAX.
pop ebp
The function has concluded, thus the stack can be shrunk. The value at the top of the stack is “popped” back into EBP (to be used the in the function that called Foo()).
If you remember at the beginning of the function, EBP’s current value was pushed onto the stack, and then EBP was replaced with the stack pointer ESP. After the function finished, the value that EBP had at the beginning of the function was given back to EBP. The stack is dynamic storage, don’t think of it as anything else.
retn
“Near Return”. Don’t worry about the disparities of the types of ret’s yet. This simply exits the function and returns the instruction pointer (EIP) to the calling function.
How does it know where to go?
Well, if EBP+12 had the second parameter, and EBP+8 had the first parameter, what’s at EBP+4? That would be the return address. Since we popped a value off of the stack just beforehand, and ESP is equal to EBP, the return address is now at ESP. ret pops the return address off of the stack and has the instruction pointer jump into it. Now, the code flow goes back to the calling function.
Wait, what about the return value? Where does bar + baz go?
bar + baz is stored in EAX. The return value of every function is stored is stored in EAX.
When decompiling some
voidfunctions, you’ll see a bizarre return value sent back. This is because EAX was used somewhere earlier, and the decompiler thinks that its value is being returned.
This was a mouthful. For someone just starting out (especially if you have very little programming experience), you will surely need to re-read this a few times to get a good understanding. Reverse engineering is an art-style, and assembly is just the cusp of what reverse engineering and malware analysis entails. If you’re struggling, what I do and have done when trying to understand difficult methodology is to say it out loud. “This happens because of this”. Rubber Duck Debugging is also useful in this aspect.
If you want reading material, Practical Malware Analysis by Michael Sikorski is the bible of malware analysts. It even has labs for you to follow along and do.
I also encourage you to also write basic C programs, compile, and disassemble them (with any of the above disassemblers).
My DMs are open on Twitter, so if you still have questions, don’t be afraid to shoot me something.